
Our customer is a prominent player in e-learning solutions globally, based in India. We are associated with them since past 1 year through multiple projects on AWS cloud platform along with major DevOps tools, including Docker and Kubernetes.

During our discussion with customer SPOC {VP-Technology} we zeroed in for following goals:
- Migrate Data from on-prem data warehouse to AWS Redshift
- Remove single point of failures
- Create a staging environment
- Create data-pipelines and configure alerts on pipeline failures

By utilizing principles of AWS’ well architected framework, we implemented following solution:
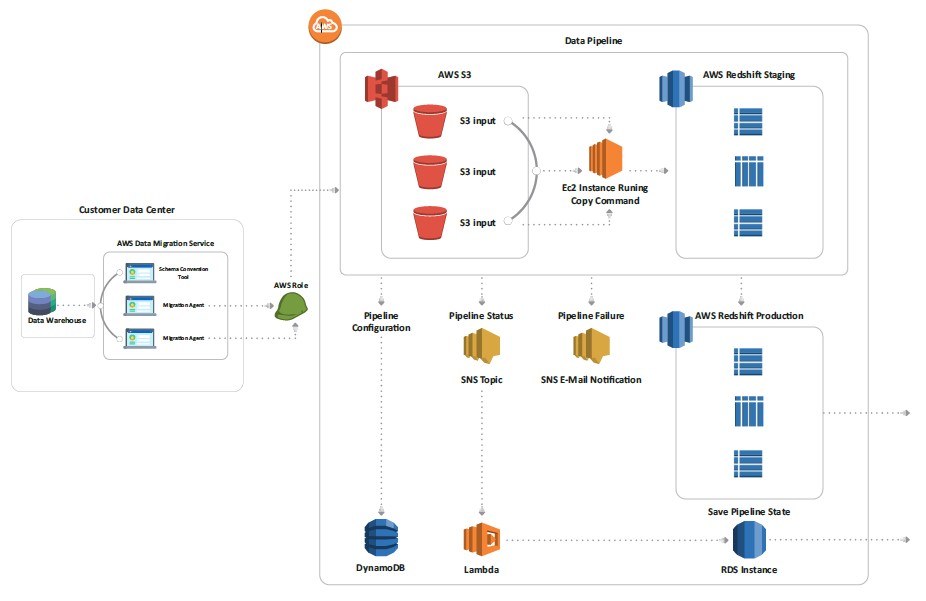
- Deployed AWS Schema Conversion Tool (SCT) on the customers premises for schema conversion and data migration
- Moved Data to S3 from the user’s on-premises data warehouse
- Created Data Pipelines on AWS
- Copied Data to AWS Redshift in staging environment using highly available EC2 instances
- Saved Pipeline statistics to RDS instances for Analytics
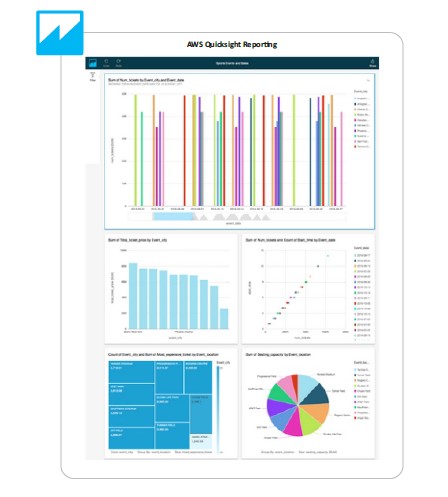
- Created a AWS Quicksight Dashboard for Redshift and RDS instances data
This solution used following tool, platforms, services and programming languages:
- Public cloud platform–AWS. Following services are prominently used:
- Simple Storage Service (S3)
- Elastic Compute Cloud (EC2)
- AWS Redshift
- SNS for Pipeline alerts and notifications
- Lambda to save Pipeline stats on RDS
- RDS to save Pipeline statistics
- Dynamodb for pipeline configurations
- AWS IAM Role to allow SCT to put records on S3
- AWS Quicksight for Analytics
Click to see large view

Based on changes implemented as per AWS’ well architected framework, customer gained following in addition to predefined goals:
- Improved performance with RedShift
- Fast scaling with fewer complications to meet the changing storage demands
- Better security with SSL encryption for data in transit
- Notifications for pipeline failures
- Detailed statistics on QuickSight